Um dos meses especiais em relação à participação dos estudantes e professores. As Festas Juninas no Nordeste ainda continuam espalhando sua magia. Não seria diferente no Colégio Estadual Tiradentes, pois o empenho de toda a equipe ratificou o que já se esperava: uma das melhores festas do ano, com certeza. A participação da comunidade, a presença de ocnvidades, alunos egressos, crianças, adultos e melhor idade. Um show!
Aproveitamos esta oportunidade para agradecer com sinceridade a toda equipe escolar, desde os primeiros momentos, na organização e aquisição de materiais, na formação dos grupos, nos ensaios, na ornamentação, nas pinturas, nos artesanatos, em tudo enfim.
Nesse momento, percebeu-se o quanto a união do grupo, o empenho dos estudantes e a sintonia com a comunidade chega a um resultado espetacular.
Assim, desde a equipe de limpeza, às merendeiras, aos auxiliares de secretaria, aos porteiros, à gestão…
E em especial, à comissão organizadora que, juntamente com os estudantes, deram uma demonstração de que tudo quanto for proposto e encarado com responsabilidade traz bons resultados.
Um dos pontos que mais me chamaram a atenção foi a harmonia entre os turnos em que houve participação de diversos estudantes e professores numa mistura saborosa de talento, bom humor e arte da mais pura qualidade.
Agradecimentos aos jurados, que contou com a participação de pessoas da comunidades, ex-professores e diretora, lideranças estudantis da região, e muito mais. No final, a presença sempre marcante da Banda de Forró Seu Luiz que deu seu show particular, numa parceria que já dura anos. Nosso abraço caloroso a todos que colaboraram, contando com isso para as próximas edições, na fé e na esperança.
O Colégio Estadual Tiradentes é grato a todos!
No final desse mês, já se percebia os primeiros movimentos relacionados ao Projeto Junino. As áreas ligadas às artes trabalharam bastante nos preparos para o que viria a seguir.
Visitas a projetos de reciclagem e ao Complexo Solar Sol do Sertão…
ABRIL
–
MARÇO
–
FEVEREIRO
JORNADA PEDAGÓGICA – Neste link, você encontra todas informações sobre a primeira semana de trabalho pedagógico do ano letivo de 2023. Clique e obtenha mais detalhes.
Início do Ano Letivo para os estudantes – 06/02/2023. Nesse primeiro mês, muitos estudantes faltaram por conta da regularização do transporte escolar. Ainda assim, fez-se todo o esforço possível para manter a rotina pedagógica.
JANEIRO
Realização da Colação de Grau e Coquetel das Turmas de 3ª Série do Ensino Médio do ano de 2023, no pátio coberto da escola. O evento foi um sucesso. A presença das famílias e de pessoas da comunidade marcou esse evento, resgatando um pouco da tradição de anos anteriores, especialmente antes da Pandemia do COVID-19.
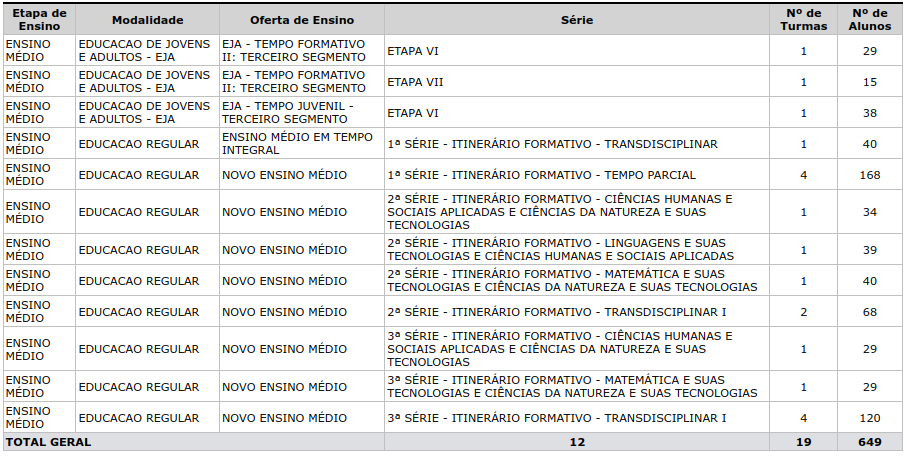
Realização das Matrículas para o ano de 2023, totalizando 19 turmas, incluindo uma turma de Ensino Integral e uma de EJA Juvenil.
NÚMEROS ATUAIS – Em: 03/07/2023
NOSSOS CANAIS DE COMUNICAÇÃO & DIVULGAÇÃO
Visite esses links e acompanhe suas e nossas atividades!